Google Crawled but Not Indexed? Here’s How to Fix It
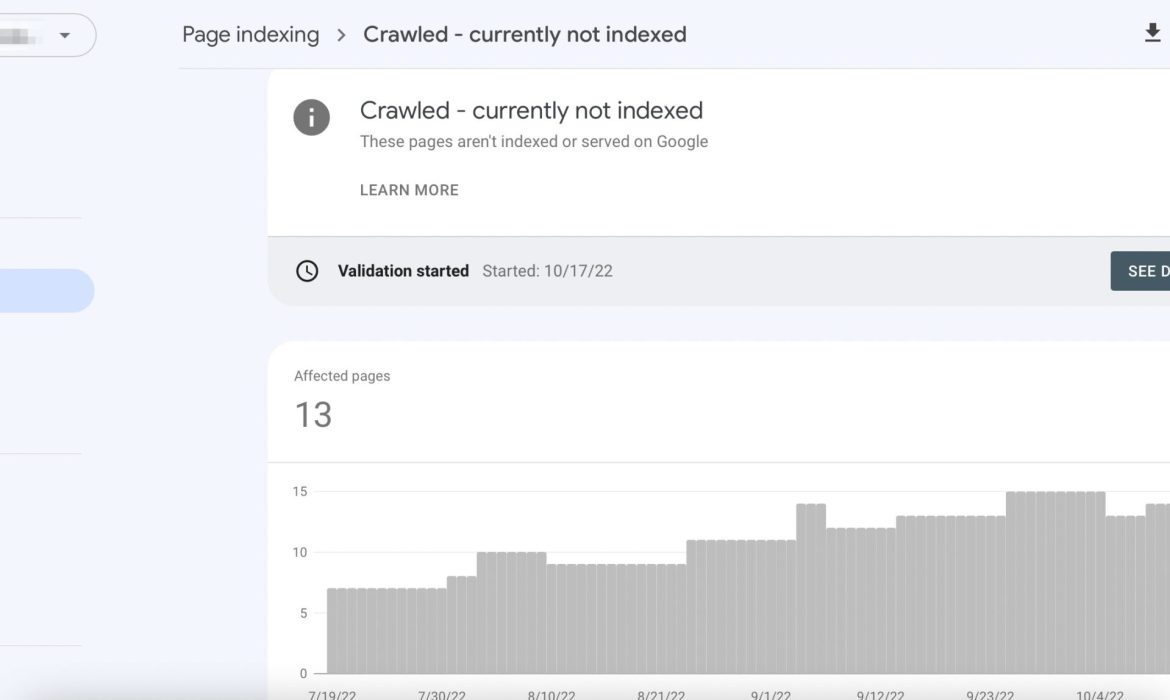
You’ve published a new page, optimized it for SEO, and waited patiently, only to find a frustrating message in Google Search Console: “page is not indexed: crawled – currently not indexed.”
This can be confusing. If Google has already crawled the page, why isn’t it indexed and visible in search results?
To clear things up: crawling is when Googlebot visits your page, and indexing is when that page is added to Google’s searchable database. A page that’s crawled but not indexed means Google saw it, but decided not to list it (yet).
This scenario can hurt your site’s visibility, especially if you rely on organic traffic. Fortunately, it doesn’t always mean something’s broken, though there may be improvements needed.
In this post, we’ll explore the common reasons behind this issue and walk you through how to fix crawled but not indexed pages, so your content gets the attention it deserves.
Understanding the Issue: Crawled But Not Indexed
What Does ‘Crawled – Currently Not Indexed’ Mean?
When you see the status “Crawled – currently not indexed” in Google Search Console, it means that Googlebot has visited your page but hasn’t added it to its search index, so the page won’t appear in search results.
This can feel like a red flag, but in most cases, it’s not a penalty. In fact, it’s a fairly common scenario, especially for newer or lower-priority pages. Google evaluates every crawled page based on quality, relevance, and user value before deciding whether it deserves a spot in the index.
Sometimes, this decision is temporary, Google might revisit and index the page later. In other cases, it’s intentional if the page is seen as duplicate, thin in content, or lacking unique value.
Understanding why your page is crawled but not indexed is the first step toward fixing it, and ensuring your content reaches your target audience through search.
Where You’ll See It
If you’re wondering where this mysterious “crawled – currently not indexed” status actually shows up, you’ll find it in Google Search Console, your go-to dashboard for understanding how Google sees your site.
Head over to the “Pages” report (previously under “Coverage”), and you’ll see a list of URLs grouped by their indexing status. Among them, you might spot the dreaded message:
“Crawled, currently not indexed.”
This label means Googlebot visited the page, processed it, but ultimately didn’t index it, at least not yet.
Here’s what the message typically looks like:
- Status: Crawled – currently not indexed
- Last crawled: [date]
- Why it matters: The page was crawled but not added to the index.
It’s like being invited to a party, showing up, and then not being allowed inside, not because you did anything wrong, but because the host wasn’t sure you added value to the guest list.
Common Reasons for Crawled But Not Indexed Pages
If Google has taken the time to crawl your page but still hasn’t indexed it, there’s likely a reason. While it’s not always a sign of something “broken,” it usually points to areas that need improvement. Let’s start with one of the most common culprits:
1. Low-Quality or Thin Content
Google wants to serve valuable, in-depth, and original content to its users. If your page lacks substance, or offers information that’s already widely available, Google may decide it’s not worth indexing (at least for now).
Here are a few signs of low-quality or thin content:
- Your page has only a few lines of text.
- The content repeats what’s already found on other indexed pages (on your site or elsewhere).
- It’s missing depth, insight, or uniqueness that would make it stand out.
Duplicate content can also trigger this status. If Google sees your page as too similar to others, especially those already indexed, it may skip it altogether.
2. Crawl Budget Limitations
If you’re running a large website with hundreds, or thousands, of pages, Google might not crawl and index every single one. That’s where the concept of crawl budget comes into play.
What is the Crawl Budget?
Crawl budget is essentially the number of pages Googlebot is willing (and able) to crawl on your site within a given timeframe. It’s influenced by factors like:
- Your server’s performance and speed
- How frequently your content is updated
- The overall importance and structure of your pages
When your site exceeds this invisible budget, Google may choose to crawl a page, but delay or skip indexing it, especially if the page seems low-priority.
This is common for:
- E-commerce sites with endless product pages
- News portals with daily updates
- Blogs with lots of tag or category pages
To get around this, prioritize your most important content, clean up low-value pages, and improve internal linking to guide Googlebot more efficiently.
3. Slow Page Load or Technical Errors
Sometimes it’s not your content or crawl budget that’s holding you back, it’s the technical side of your website.
When Googlebot tries to crawl a page and runs into issues like slow loading speeds or server errors, it may decide not to index the page at all.
Think of it like walking into a store with the lights off and no one at the counter—you’ll probably leave right away. These technical barriers, much like broken links or poor loading experiences, can quietly sabotage your indexing efforts. If you’re working on strengthening your SEO signals, you might also want to check your backlinks using Google Search Console to ensure your pages are earning the authority they deserve.
Common Technical Issues That Can Affect Indexing:
- JavaScript Rendering Problems:
If your content relies heavily on JavaScript and isn’t rendered properly, Googlebot might crawl the page but miss the actual content, causing it to skip indexing. - 5xx Server Errors:
These server-side errors (like 500 or 503) tell Google that your site is temporarily unavailable. If it happens during the crawl, indexing is likely put on hold.
To fix this, improve your site speed, check server logs, and use tools like Google’s URL Inspection Tool or Lighthouse to diagnose and resolve performance issues.
4. Improper Canonical Tags
Canonical tags are meant to help Google understand which version of a page you want indexed when similar or duplicate content exists. But when used incorrectly, they can silently sabotage your indexing efforts.
How Canonical Tags Affect Indexing:
If you’ve added a canonical tag to a page that points to another URL, you’re essentially telling Google,
“Hey, this other page is the main version, please index that instead.”
So even if your page is crawled, Google may choose to honor the canonical directive and not index it.
This often happens unintentionally, like:
- Copying meta tags from another page without updating the canonical URL
- Using self-referencing canonicals that point to a different page
- Letting your CMS auto-generate incorrect canonical URLs
To fix this, always double-check your canonical tags and ensure they reflect the page’s true identity, especially on unique or valuable content.
5. No Internal Links or Orphaned Pages
Your content might be live and even crawled, but if no other pages on your site link to it, Google may see it as unimportant or disconnected. These are called orphaned pages, pages that have no internal pathways pointing to them.
While Googlebot can still find them through your sitemap or external sources, internal linking is a strong signal of relevance and priority. Without it, your page might get crawled but left out of the index.
To fix this, link to your target page from:
- Relevant blog posts
- Category or pillar pages
- Your homepage or main navigation (if applicable)
6. Content Still Being Evaluated
If your page is new, or your site is relatively young, Google might simply need more time. It doesn’t always index content immediately, especially if:
- Your site lacks authority
- The content is part of a large batch of new pages
- Google is still assessing its value
This isn’t necessarily bad; it’s more like a “waitlist” while Google decides if your page deserves a spot in the index. Give it a few days or weeks, but if it’s still not indexed after that, it’s time to investigate deeper.
How to Fix Crawled – Currently Not Indexed
1. Improve Your Content Quality
One of the top reasons Google crawls your page but chooses not to index it? Low perceived value.
If your content is shallow, lacks structure, or simply blends in with the crowd, Google’s algorithm might decide it’s not worth showing in search results, yet. To turn that around, focus on quality that stands out.
Add Depth and Structure: Go beyond surface-level information. Provide unique insights, explain the why and how, and include real-life examples, step-by-step guides, or data. Break your content into clear sections with headings, bullet points, and visuals to improve readability and engagement.
Incorporate Media: Images, videos, infographics, and embedded tools not only enhance user experience but signal value to Google. Rich media shows that your page is useful and interactive.
Use Keywords Naturally: Include your focus keyword (e.g., google crawled but not indexed) and related terms throughout the content, but avoid stuffing. Strategic placement in headers, intros, and meta tags helps Google understand your page’s relevance.
2. Strengthen Internal Linking
Even great content can go unnoticed if it’s stranded. That’s where internal linking comes in, it’s how you guide Google (and users) through your website.
When you link to a new or under-indexed page from existing, high-authority pages on your site, you signal to Google that the page matters. Think of it as handing Googlebot a glowing trail that says, “Hey, follow me, this content is important.”
Link From Relevant, Already Indexed Pages: Identify related pages that are already ranking or indexed, and add natural, contextual links pointing to your target URL. This not only improves crawlability but also builds topical authority and SEO value.
For example:
- Link from a related blog post discussing SEO indexing issues.
- Add the page to a hub or pillar page on technical SEO or site audits.
Don’t just bury links in footers, place them where they add context and value to the reader.
3. Request Indexing in Google Search Console
Sometimes, all your page needs is a little push, and Google gives you that option through the URL Inspection Tool in Google Search Console.
If your page has been crawled but still isn’t indexed, you can manually request indexing to signal that the content is ready for Google’s spotlight.
How to Do It:
- Log in to Google Search Console.
- In the top search bar, paste the full URL of the page you want indexed.
- Wait while Google retrieves data about the page.
- If it shows “Crawled – currently not indexed”, click the “Request Indexing” button.
This action queues your page for re-crawling and re-evaluation. It doesn’t guarantee indexing, but it can speed things up, especially after you’ve made improvements to the content or structure.
Pro Tip: Don’t overuse this feature. Save it for key pages or after making significant updates.
4. Inspect Technical SEO Issues
Even if your content is top-notch, technical issues can quietly block Google from indexing it. Think of technical SEO as the foundation, if it’s shaky, your page might never make it into search results. To uncover hidden problems, use trusted tools like Screaming Frog, Ahrefs, SEMrush, or Google’s URL Inspection Tool. These can help you spot issues that might be preventing indexing.
Key Areas to Audit:
- Canonical Tags: Ensure your page has the correct canonical tag. If it mistakenly points to a different URL, Google might skip indexing.
- Mobile-Friendliness: Google uses mobile-first indexing, so if your page isn’t responsive or has rendering issues on mobile, that’s a red flag.
- Site Speed: Slow-loading pages can frustrate users, and Googlebot. Use tools like PageSpeed Insights or Lighthouse to identify and fix speed bottlenecks.
Fixing these issues can dramatically increase your chances of getting indexed, and ranking.
5. Ensure Proper Sitemaps and Robots.txt Configuration
Two often-overlooked technical elements that directly impact indexing are your XML sitemap and robots.txt file. If either one is misconfigured, Google may crawl your page but skip indexing it, or not crawl it at all.
Submit an Updated XML Sitemap
Your XML sitemap helps Google discover and prioritize important URLs on your website. If your new or updated page isn’t listed in the sitemap, it may not be indexed quickly, or at all.
- Ensure the sitemap includes all key URLs.
- Keep it clean, avoid including broken, redirected, or noindexed pages.
- Submit your sitemap through Google Search Console under the “Sitemaps” tab.
Check robots.txt for Blocking Rules
The robots.txt file tells search engines which parts of your site they’re allowed to access. If your page or folder is being disallowed, Google might crawl it inconsistently, or not at all.
Use tools like the robots.txt Tester in GSC to confirm that no disallow rules are unintentionally blocking access to the page.
6. Build Backlinks to the Page
Backlinks remain one of the strongest signals of authority and trust for Google. If your page is crawled but not indexed, it might be because Google doesn’t yet see it as important or valuable enough, and backlinks can change that.
When other reputable websites link to your page, it signals to Google that the content has value, is trustworthy, and deserves a place in the search index.
How to Build Backlinks Effectively:
- Promote your content through outreach, forums, or social media.
- Publish guest posts with links back to your target page.
- List your content on relevant directories or resource pages.
- Get cited in niche blogs or industry roundups.
Even a few high-quality backlinks can tip the scale and get your page indexed, especially when combined with strong content and internal links.
When to Wait and When to Act
Not every page needs immediate action after being crawled but not indexed. Sometimes, the best move is to simply wait; other times, a deeper investigation is needed. The key is knowing when patience is enough and when proactive fixes are required, like improving technical SEO or investing in strategic link building services to boost your page’s authority and indexing potential.
When to Wait
If your page is brand new, give Google some time.
It’s normal for indexing to take a few days to a couple of weeks, especially for new domains or websites with lower authority. Google often revisits pages later to reevaluate them for indexing.
When to Act
If your page has been sitting in the “Crawled – currently not indexed” status for several weeks or even months, it’s time to take action. This is a sign that something’s off, whether it’s quality, technical SEO, or site structure.
Check the “Last Crawled” Date in GSC
In Google Search Console, use the URL Inspection Tool to see the “Last crawled” date.
- If the page hasn’t been crawled recently, it might need better internal links or a sitemap update.
- If it was crawled recently but still isn’t indexed, revisit content quality and technical factors.
Bonus: How to Monitor Indexing Efficiently
Staying on top of your site’s indexing health shouldn’t be a guessing game. With the right tools and a regular routine, you can catch and fix issues before they impact your SEO.
🔧 Essential Tools to Monitor Indexing:
- Google Search Console (GSC):
Your primary source for indexing insights. Use it to track crawl status, indexing errors, and performance. - Index Coverage Report:
Found in GSC, this report shows which pages are indexed, excluded, or have errors. It helps identify trends or recurring problems. - URL Inspection Tool:
Use this to check individual pages for crawl and indexing status, view the last crawl date, and submit pages for indexing.
Schedule Regular Audits
If you manage a large site, set up monthly or quarterly SEO audits to review indexing health, especially for newly published or updated content. This ensures nothing slips through the cracks as your site grows.
Conclusion
Seeing the message “page is not indexed: crawled, currently not indexed” can be frustrating, but it’s not the end of the road. More often than not, it’s a signal, not a punishment, that your content needs refinement, better structure, or stronger technical foundations.
To fix the issue, start by improving your content depth and optimizing it with relevant keywords. Strengthen your internal linking strategy by connecting the page to other valuable content on your site. Use Google Search Console to manually request indexing and monitor crawl activity.
Inspect your site for technical SEO issues that might be blocking proper indexing. Also, ensure your XML sitemap is up to date and your robots.txt file isn’t accidentally preventing access. Finally, build quality backlinks to signal authority and trust to Google.
If your page isn’t indexed, don’t panic, follow these steps and stay consistent. SEO success comes with patience, persistence, and a commitment to quality.
Frequently Asked Questions
Indexing time can vary. Some pages get indexed within a few hours, while others take days or even weeks. Factors like website authority, internal linking, and crawl frequency all influence the timing.
Yes. If Google finds that your page content closely resembles existing indexed pages, on your site or elsewhere, it may choose not to index it, assuming it adds little new value.
Not always. First, try optimizing the page. If the content is outdated, irrelevant, or offers no SEO value even after improvements, it might be better to remove or consolidate it.
Absolutely. Linking to the target page from other relevant, indexed content helps Google discover and evaluate it more effectively. The more contextual signals, the better.
Yes. Slow-loading pages can hinder Google’s ability to crawl and assess content efficiently. While it won’t stop indexing altogether, it can delay it or reduce crawl frequency.


